All services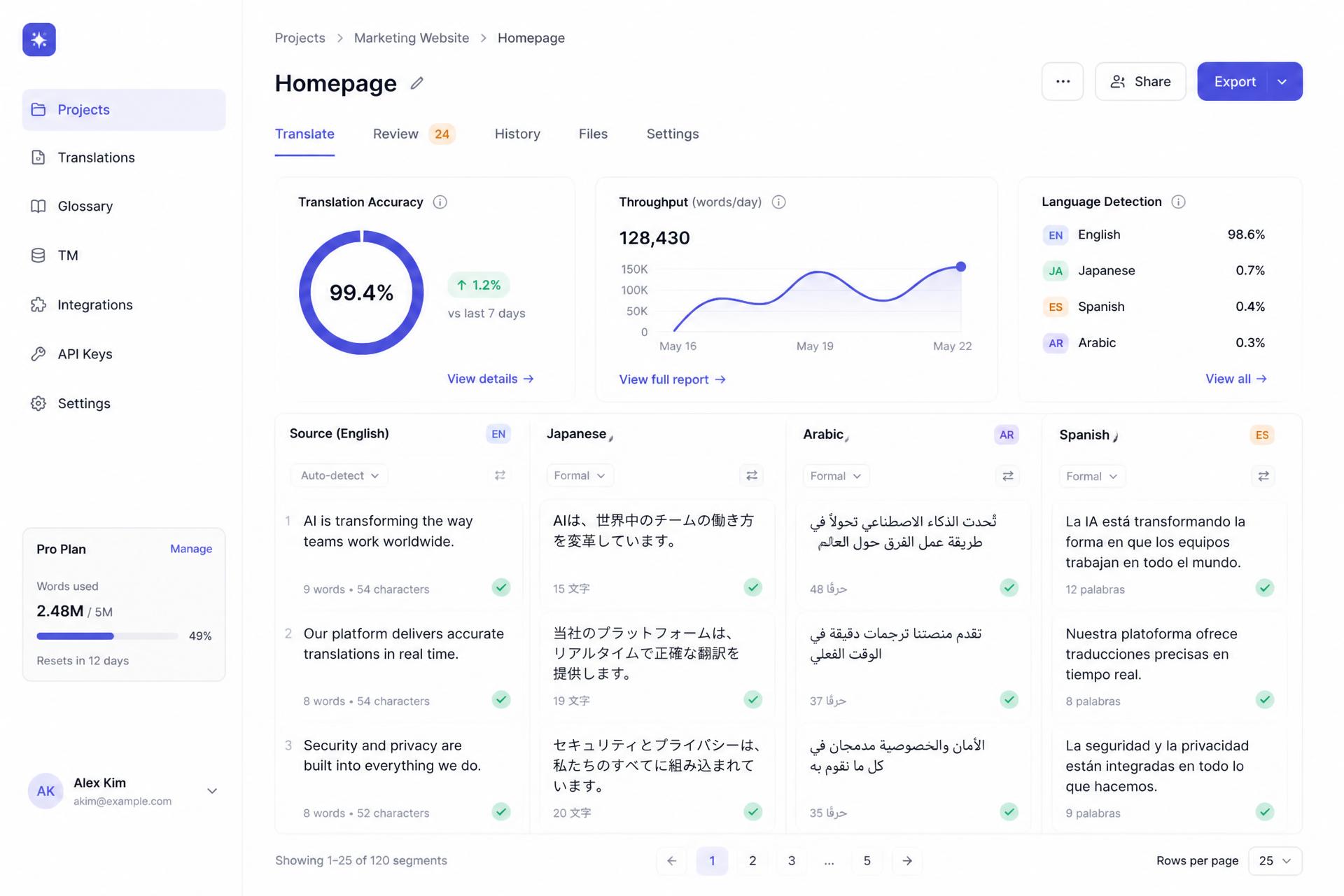
New
RAG Pipelines
Retrieval that actually grounds your LLM.
Production-grade retrieval-augmented generation — ingestion, chunking, embeddings, hybrid search, re-ranking, and evals. Tuned to your domain, observable end-to-end.
>90%
Retrieval precision
Cited
Every answer
Evals
On every change
What's included
- Ingestion + chunking strategies tuned to your data
- Hybrid retrieval (vector + keyword + metadata)
- Re-ranking and query rewriting
- Citation, grounding, and hallucination guards
- Eval harness with golden datasets
- Cost + latency observability dashboards
Frequently asked
Which vector DB do you use?+
pgvector, Pinecone, Weaviate, Qdrant, or Turbopuffer — chosen per workload and budget.
Do you handle private data?+
Yes. We deploy into your VPC and never send sensitive data to third-party APIs without your approval.
Do you support multimodal RAG?+
Yes — text, PDF, images, and audio.
Ready when you are
Let's build something intelligent.
Tell us about your project. We'll get back within one business day with a tailored response — not a generic deck.